UnifAPI vs TinyFish: public-data APIs vs. browser agents

TinyFish automates websites with Search, Fetch, Browser, and Agent APIs. UnifAPI gives agents structured public data behind one key. Here's when to use each.
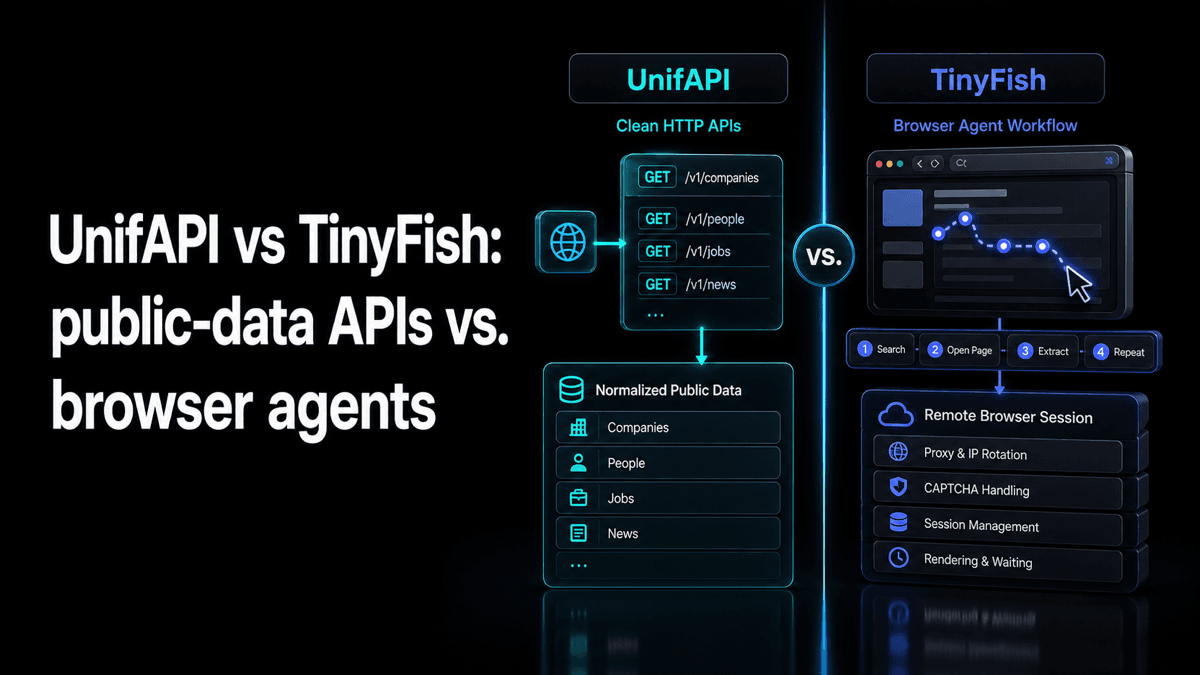
TinyFish and UnifAPI both answer the same 2026 question: how does an AI agent use the web without a human copy-pasting pages into a prompt? The answer splits into two very different layers. TinyFish is browser-agent infrastructure: Search, Fetch, Browser, and Agent APIs that can render pages, drive workflows, fill forms, and return extracted results. UnifAPI is a public-data gateway: platform-native endpoints for social and open-web records, normalized behind one API key and one response envelope.
If you're searching for a TinyFish alternative, the first decision is not vendor vs. vendor. It is browser workflow vs. structured data API. Pick TinyFish when the agent genuinely has to operate a website. Pick UnifAPI when the data already has a repeatable public surface and the browser would only add latency, cost, and failure modes.
TinyFish vs UnifAPI: the quick answer
| Dimension | TinyFish | UnifAPI |
|---|---|---|
| Core abstraction | Search, Fetch, Browser sessions, and goal-driven Agent runs | Curated public-data APIs behind one key |
| Best boundary | Dynamic pages, forms, login walls, anti-bot flows, and sites without APIs | Public social, search, scrape, and news-style records where direct endpoints fit |
| Execution model | A real browser renders, clicks, waits, and extracts | HTTP calls return normalized JSON records |
| Pricing unit | Credits: Search and Fetch use 0 credits; Agent is 1 credit per step; Browser is 1 credit per 4 minutes | Records: flat $0.001 per returned record across the catalog |
| Agent integration | MCP, SDKs, CLI, Search, Fetch, Browser, Agent tools | MCP plus OpenAPI/HTTP endpoints for platform-native public data |
| When it wins | The task needs site interaction | The task needs repeatable public data at volume |
What TinyFish is optimized for
Based on TinyFish's public site and docs as of May 21, 2026, TinyFish has four surfaces. Search returns structured ranked results. Fetch renders a known URL in a real browser and returns clean content. Browser creates a remote browser session for direct Playwright or CDP control. Agent takes a natural-language goal and decides the browser actions for you.
That is a strong shape for tasks where a normal API is not enough: pulling data from a vendor portal, filling an insurance quote form, checking a dynamic catalog, or using a site that only exposes the right data after JavaScript, credentials, or multiple clicks. TinyFish is trying to make the browser programmable enough for production agents.
The trade is that a browser workflow is still a workflow. The agent has to load pages, wait for rendering, recover from UI drift, and spend credits by step or by browser-session time. When a browser is necessary, that cost is rational. When the target data is already available as a structured public record, the browser is usually the wrong abstraction.
What UnifAPI is optimized for
UnifAPI starts from the opposite assumption: most public-data agent workflows should not open a browser at all. A social-listening agent should call TikTok, Reddit, YouTube, LinkedIn, Instagram, Twitter/X, Threads, or the China-market platforms through stable endpoints. It should receive records with pagination, metadata, and predictable errors. It should not reason about DOM nodes.
The product surface is intentionally narrower than a full browser platform. UnifAPI does not log into the user's private accounts, click buttons, or complete forms. It gives agents the public-data layer: one auth header, one bill, one envelope, and a flat $0.001 per record returned. For high-volume research, monitoring, creator discovery, competitive intelligence, and market analysis, that unit is easier to budget than browser minutes or agent steps.
Pricing: credits vs records
TinyFish's public pricing page makes Search and Fetch free, then bills Agent at 1 credit per step and Browser at 1 credit per 4 minutes, with pay-as-you-go listed at $0.015 per credit and lower per-credit rates on subscription plans. A five-step Agent run on pay-as-you-go is roughly $0.075. A 16-minute Browser session is roughly 4 credits, or $0.06 on pay-as-you-go.
UnifAPI bills records, not steps or time. A call that returns 20 records costs $0.02. A 50-record creator-research page costs $0.05. Empty results still bill one record because the query work happened. The comparison is not apples-to-apples: TinyFish charges for executing browser work; UnifAPI charges for returned data. The practical question is whether your workflow needs browser work in the first place.
Output shape matters for agents
TinyFish output is shaped around tasks: search results, extracted page content, a browser connection URL, or the result of an Agent run. That is exactly what you want when the agent's job is to operate a website and return a final answer.
UnifAPI output is shaped around records. The agent gets lists of posts, videos, profiles, comments, search results, and related platform metadata in a consistent envelope. That is exactly what you want when the agent has to compare, rank, filter, paginate, enrich, and revisit the same data source repeatedly.
When TinyFish is the better choice
Pick TinyFish if the website itself is the interface. Examples: sign into a supplier portal and download the latest price sheet; complete a multi-step quote form; inspect a dashboard that has no public API; extract from a JavaScript-heavy page where static fetch fails; hand your own Playwright code a stealth remote browser session.
TinyFish also makes sense when your product needs a general web-action tool exposed to an agent. The user says what they want done on a site, and the agent tries to browse, click, wait, and extract. That is not UnifAPI's lane.
When UnifAPI is the better choice
Pick UnifAPI if your agent needs public platform data rather than website interaction. Examples: monitor brand mentions across Reddit, TikTok, YouTube, and Twitter/X; pull creator profiles and recent posts; compare product launch chatter across Western and Chinese social platforms; enrich a research brief with platform-native metadata like engagement counts, comments, authors, timestamps, and pagination cursors.
In those workflows, opening a browser for every source is expensive and brittle. The agent wants data, not a screen. UnifAPI keeps the integration count at one and lets the model spend its tokens on synthesis instead of browser recovery.
Using TinyFish and UnifAPI together
The strongest architecture is often hybrid. Use UnifAPI for the repeatable public-data layer: discover posts, profiles, videos, comments, and trends through endpoints. Use TinyFish when the workflow reaches a site that has to be operated like a human would operate it: a form, account portal, protected catalog, or dynamic page with no stable data surface.
That split keeps each tool honest. UnifAPI should not pretend to be a universal browser. TinyFish should not be forced to spend browser steps on records that a direct endpoint can return faster. Put public data behind APIs, put messy websites behind browser agents, and let the agent choose the lighter tool first.
Bottom line
TinyFish is a serious choice for AI browser automation. It is especially compelling for authenticated, dynamic, or interactive web workflows. UnifAPI is the better choice for structured public-data access where the agent needs consistent records from many platforms, predictable billing, and an MCP-ready catalog.
The deciding question is simple: does the agent need to use the website, or does it need the data behind the website? If it needs the website, start with TinyFish. If it needs the data, start with UnifAPI.